NVSHMEM Multi-NIC Support with AWS EFA#
- Date:
2026-03-27
Abstract#
NVSHMEM 3.6.5 introduces multi-NIC support for the libfabric transport with round-robin NIC selection—a collaborative effort between NVIDIA and Amazon Annapurna Labs. NVSHMEM has gained significant attention since DeepEP demonstrated that implementing MoE layer dispatch and combine operations with NVSHMEM can substantially improve performance for large language models (LLMs) employing Mixture-of-Experts (MoE) architectures. However, on AWS, DeepEP compatibility was limited because it relies on InfiniBand GPUDirect Async (IBGDA), whereas AWS GPU instances support only the proxy thread transport via libfabric. Furthermore, prior to version 3.6.5, NVSHMEM supported only a single NIC, meaning each GPU could utilize only one EFA NIC for data transmission. This article reviews the new multi-NIC feature and presents experiments exploring the potential performance improvements on AWS.
Introduction#
Mixture-of-Experts (MoE) architectures rely on all-to-all collective communication to dispatch and combine tokens across expert replicas. However, conventional all-to-all implementations often become a bottleneck during LLM training due to limited overlap with computation and suboptimal bandwidth utilization. NVSHMEM addresses this by exposing a device-side API that enables developers to implement custom all-to-all kernels—such as pplx-kernels and DeepEP—with GPU-initiated networking, eliminating costly GPU–CPU context switches.
Despite these advantages, prior NVSHMEM versions (before 3.6.5) supported only a single NIC per GPU on the libfabric transport. On AWS instances equipped with multiple EFA NICs, this meant that NVSHMEM-based MoE kernels could not fully utilize the available network bandwidth, and in practice did not outperform ordinary all-to-all collective communication.
To evaluate the impact of multi-NIC support, we use the NVSHMEM device all-to-all performance tool to compare single-NIC and multi-NIC configurations. We also benchmark pplx-kernels to assess whether MoE dispatch and combine operations benefit from multi-NIC EFA on the libfabric backend.
NVSHMEM Device All-to-All#
To verify that multi-NIC round-robin is functioning correctly, we use rdmatop to monitor RDMA traffic across all EFA NICs during NVSHMEM benchmarks. The experiments follow the NVSHMEM examples in the rdmatop repository.
We run two benchmarks from the NVSHMEM perftest suite on a Slurm cluster. The first measures point-to-point put bandwidth between a single GPU per node, and the second measures device-initiated all-to-all latency across all 8 GPUs per node.
Put Bandwidth (Inter-Node, 1 GPU per Node)#
In this experiment, we launch a point-to-point job with one sender and one receiver to verify whether a single GPU can fully utilize all available EFA NICs via round-robin NIC selection.
salloc -N 2 NTASKS_PER_NODE=1 \
bash examples/nvshmem/nvshmem.sbatch \
/opt/nvshmem/bin/perftest/device/pt-to-pt/shmem_put_bw \
-b 8 -e 128M -f 2 -n 1000 -w 100
All-to-All Latency (Device, All 8 GPUs per Node)#
This experiment uses the NVSHMEM device all-to-all performance tool to determine whether all-to-all communication can fully saturate all EFA NICs when all 8 GPUs per node participate.
NODES=2 # 4, 8, 16
salloc -N ${NODES} bash examples/nvshmem/nvshmem.sbatch \
/opt/nvshmem/bin/perftest/device/coll/alltoall_latency \
-b 16 -e 1G -f 2 -n 1000 -s all
pplx-kernels All-to-All#
To assess whether real-world MoE workloads benefit from multi-NIC support, we benchmark pplx-kernels—an NVSHMEM-based implementation of MoE dispatch and combine operations used in production serving systems such as vLLM. The experiment follows the pplx example in the rdmatop repository.
salloc -N 2 bash examples/pplx/pplx.sbatch \
python3 -m tests.bench_all_to_all
Result#
The following subsections present the results for point-to-point put bandwidth and device all-to-all latency, comparing NVSHMEM 3.5.21 (single NIC) against 3.6.5 (multi-NIC).
Put Bandwidth (Point-to-Point)#
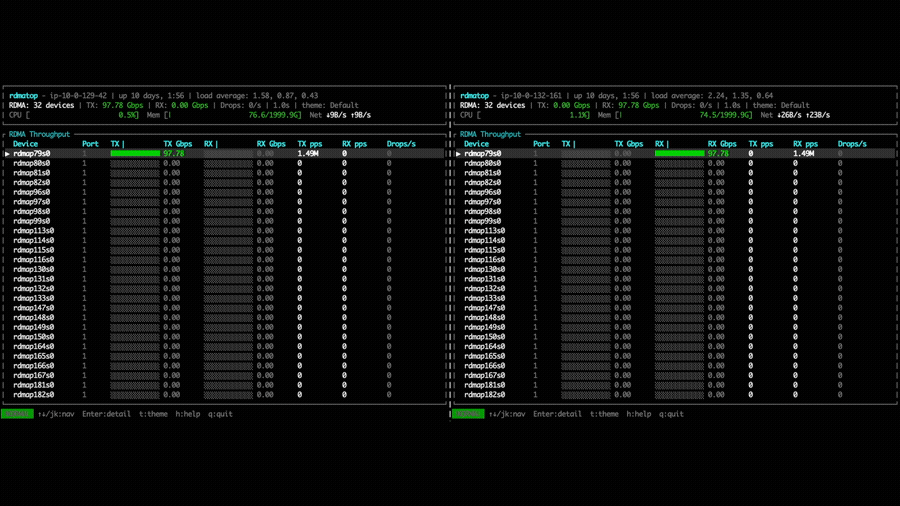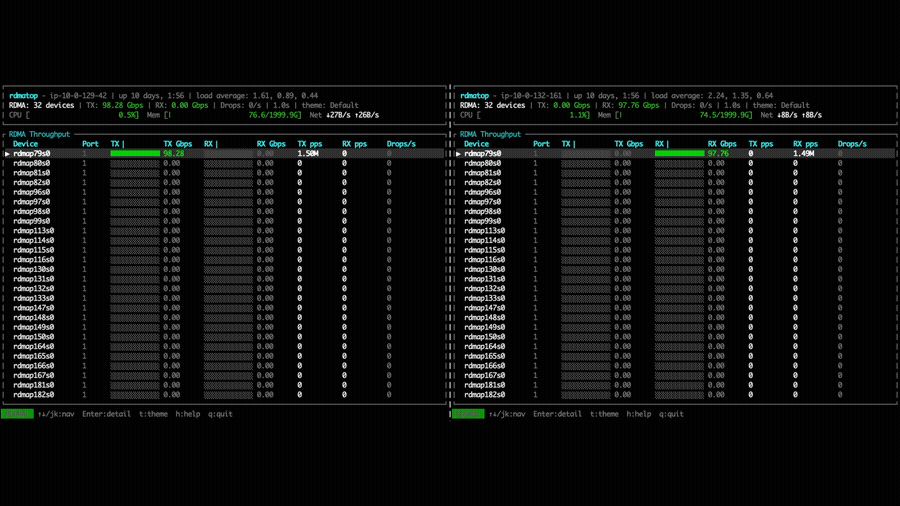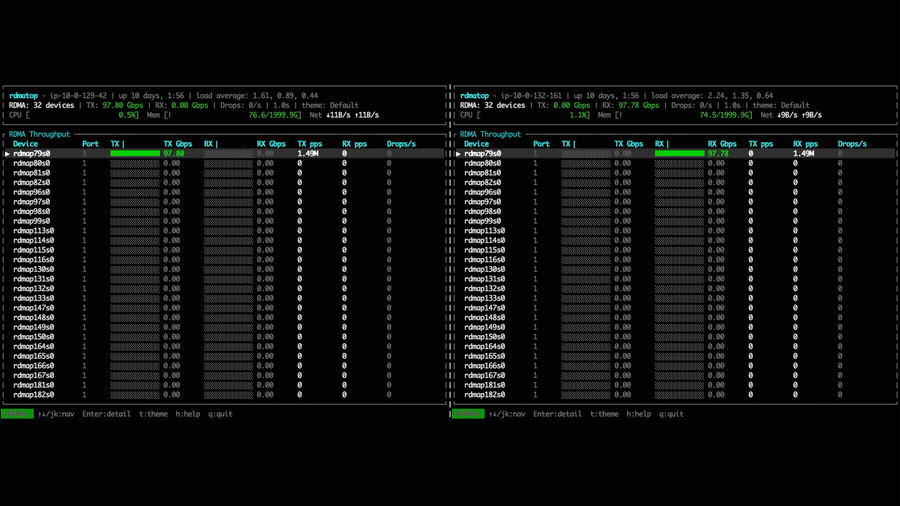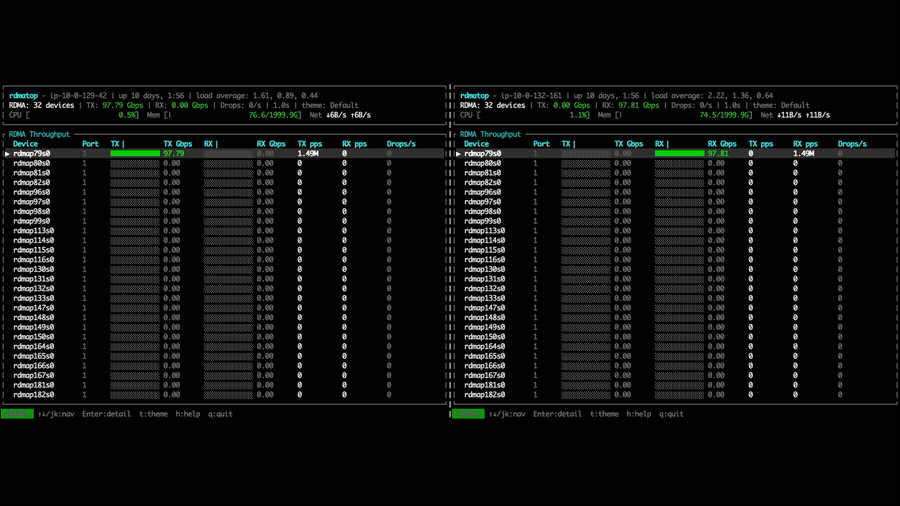
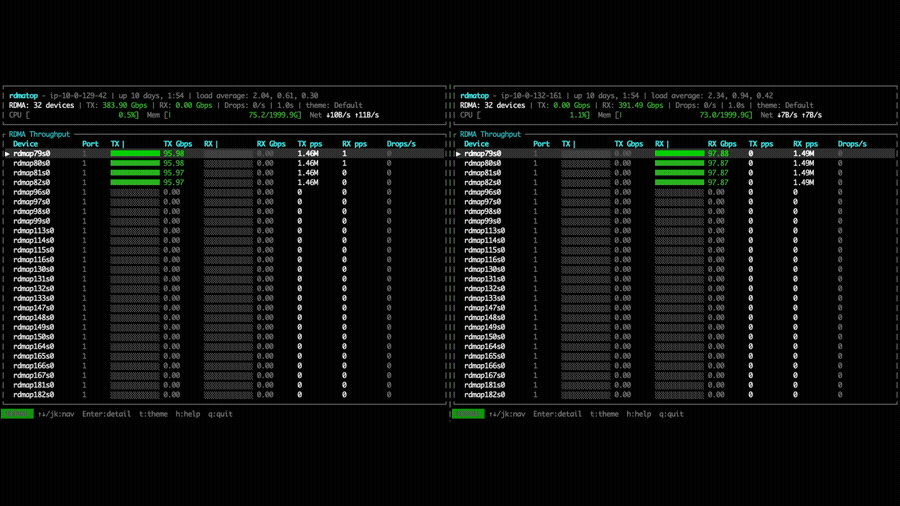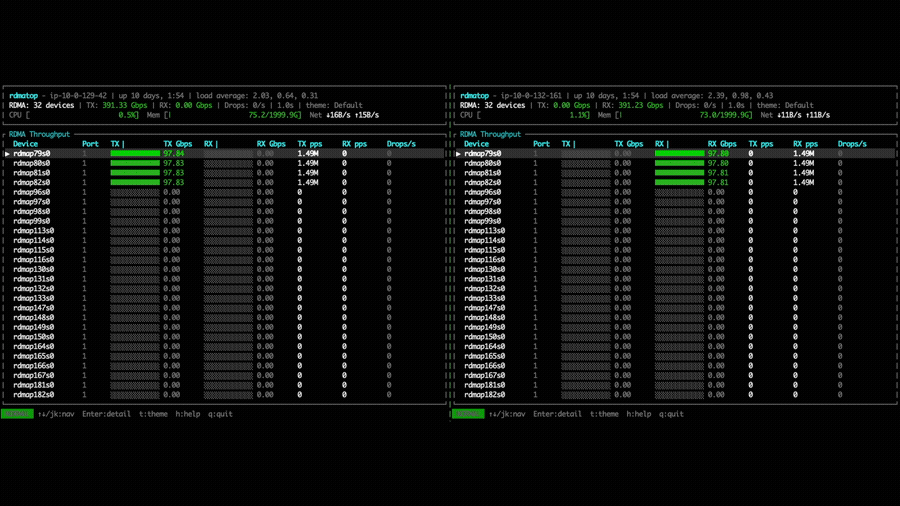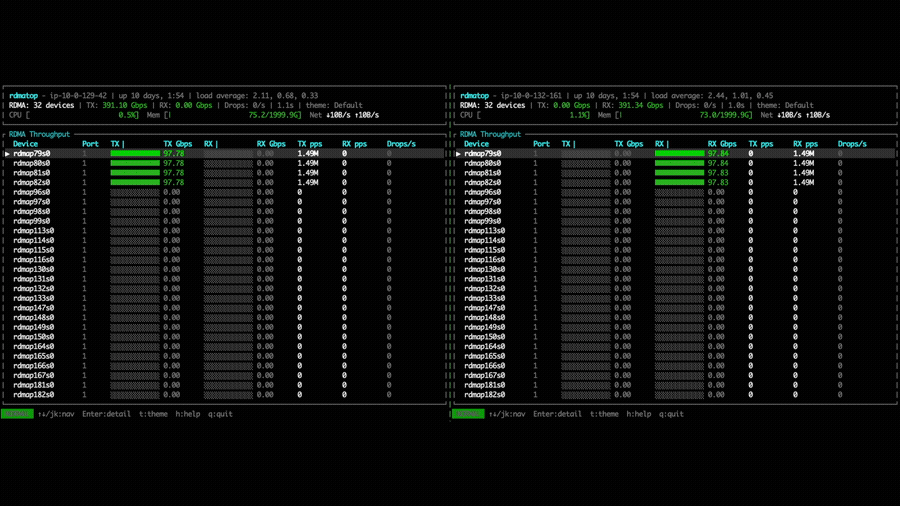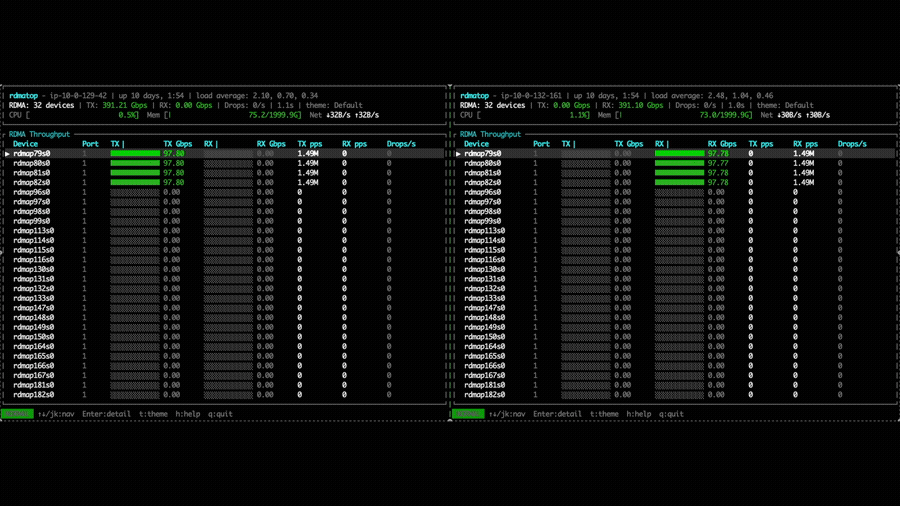
In the point-to-point put bandwidth experiment, NVSHMEM 3.5.21 uses only a
single EFA NIC per GPU for both Tx and Rx, as shown by the rdmatop output
below. This confirms that, prior to multi-NIC support, each GPU was limited to
the bandwidth of one NIC regardless of how many were available on the instance.
With NVSHMEM 3.6.5, the same experiment shows traffic distributed across all 4 EFA NICs via round-robin selection. This allows a single GPU to aggregate bandwidth from multiple NICs, significantly increasing the achievable point-to-point throughput.
All-to-All Latency (Device)#
In the device all-to-all experiment, NVSHMEM 3.5.21 shows that each GPU utilizes only a single NIC to transfer data, consistent with the point-to-point results above.
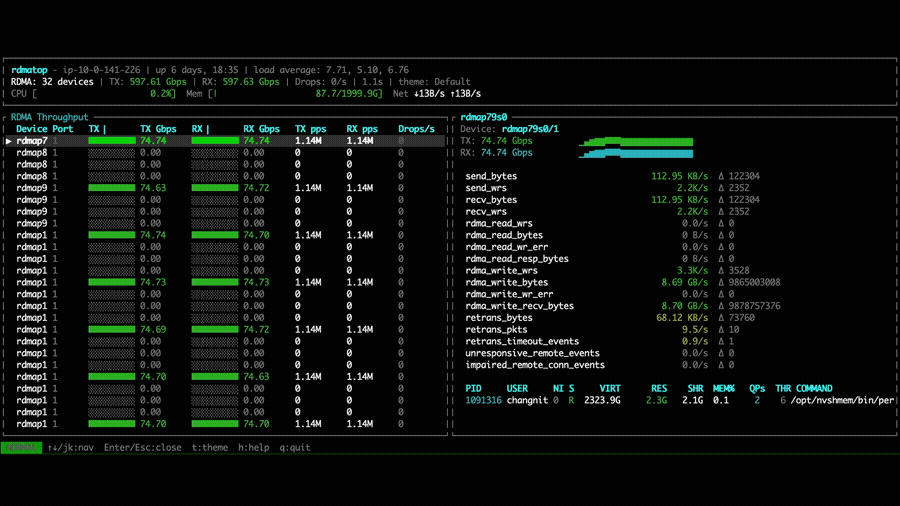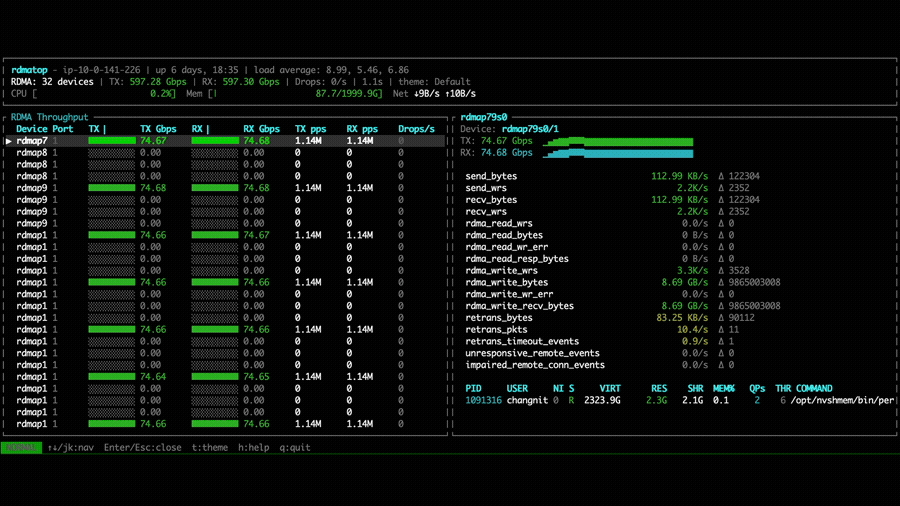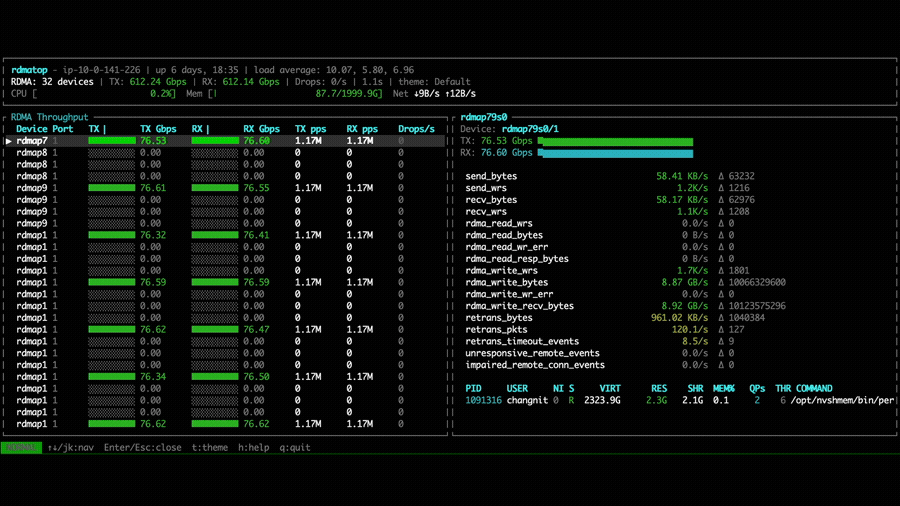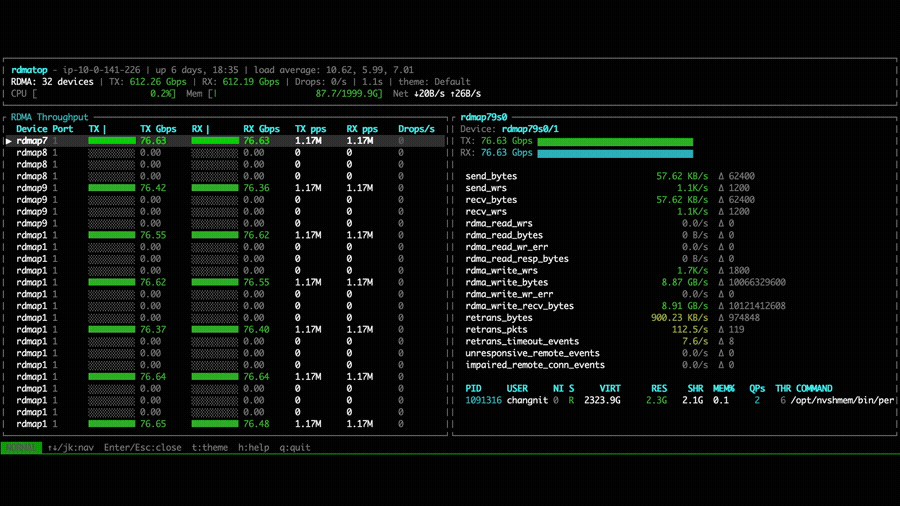
With NVSHMEM 3.6.5, rdmatop confirms that all Tx NICs carry traffic,
demonstrating that multi-NIC round-robin is active during the all-to-all
operation. However, we observed that Rx traffic was imbalanced across NICs.
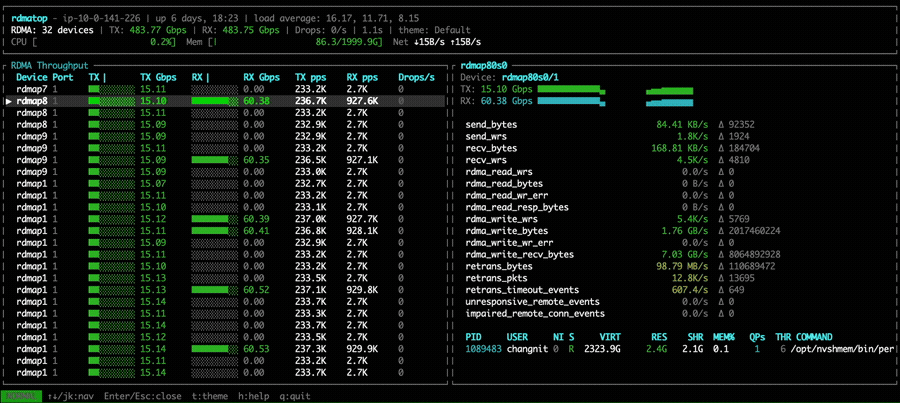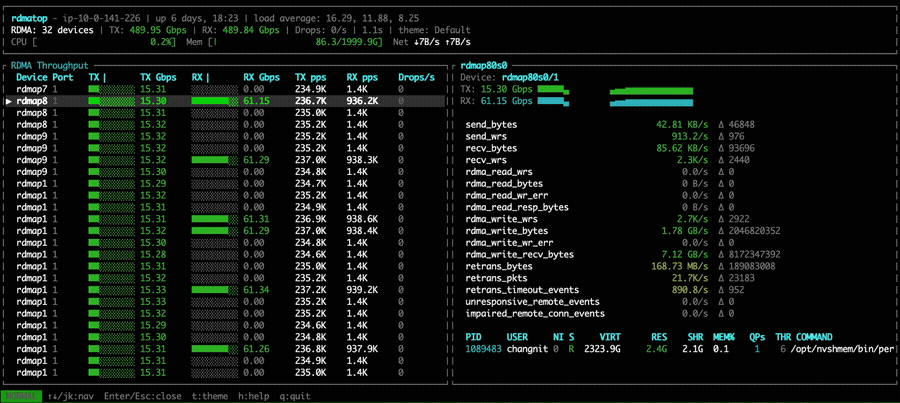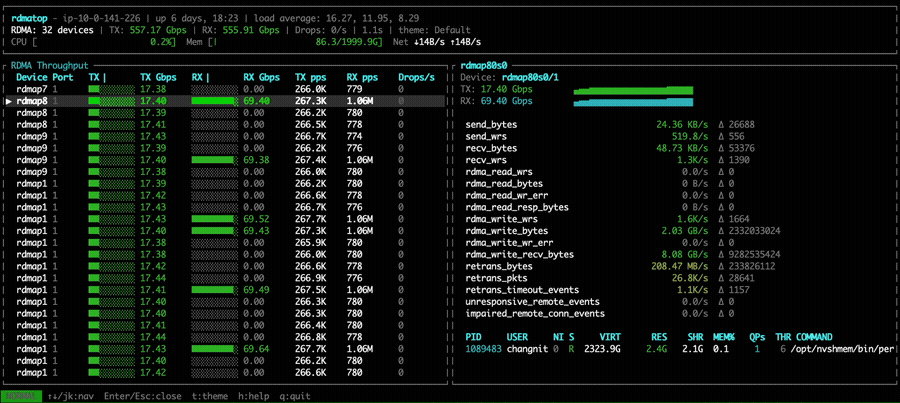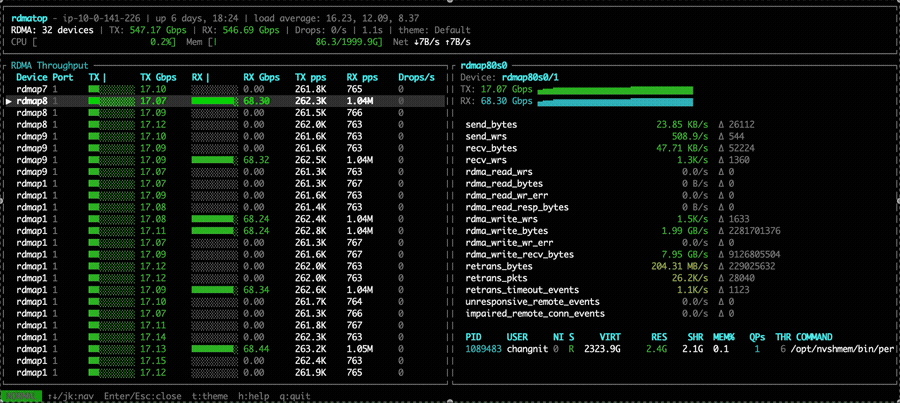
This imbalance occurs because all PEs compute the same round-robin target NIC at the same time, causing all traffic to converge on the same NIC. A fix is proposed in the PR libfabric: fix multi-NIC RX imbalance for EFA transport. After applying the fix, we can observe that Rx traffic is balanced across all NICs in the all-to-all experiment.
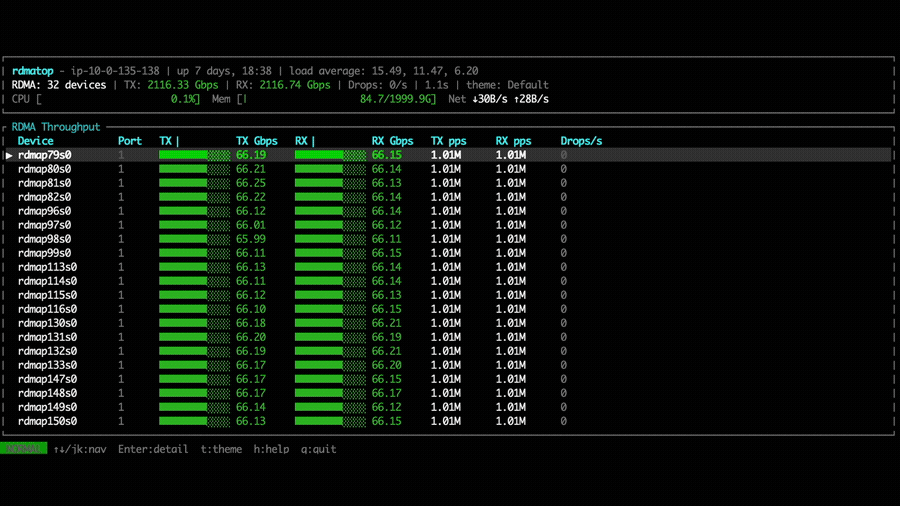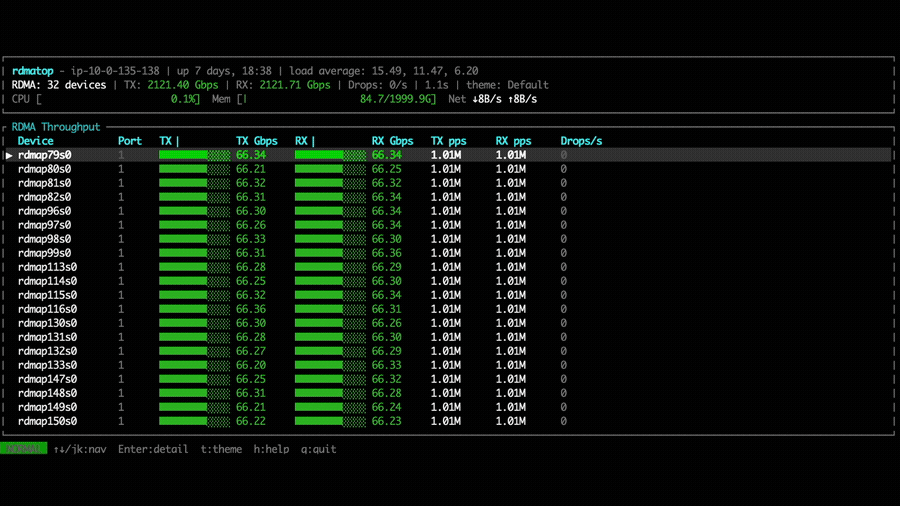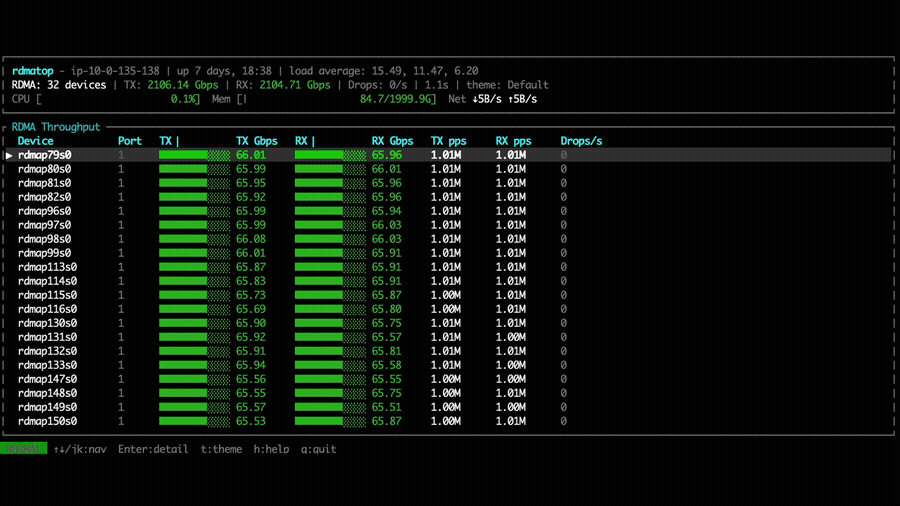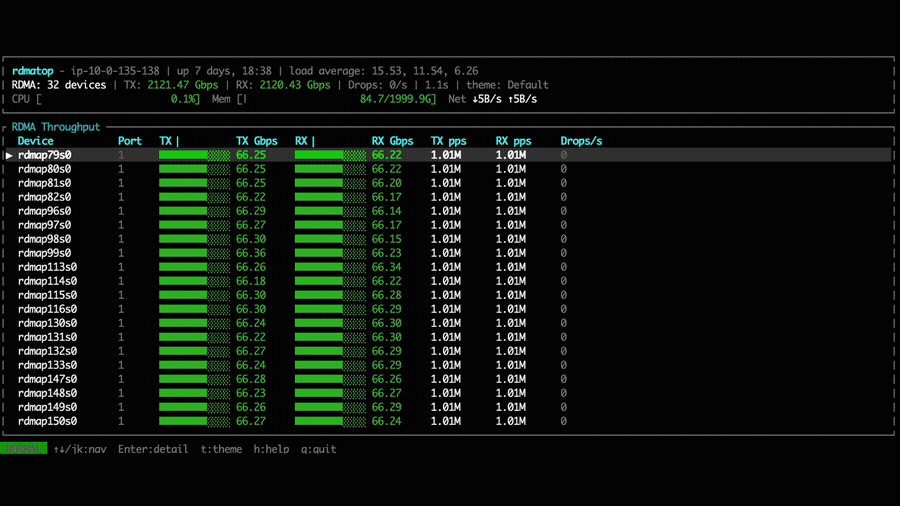
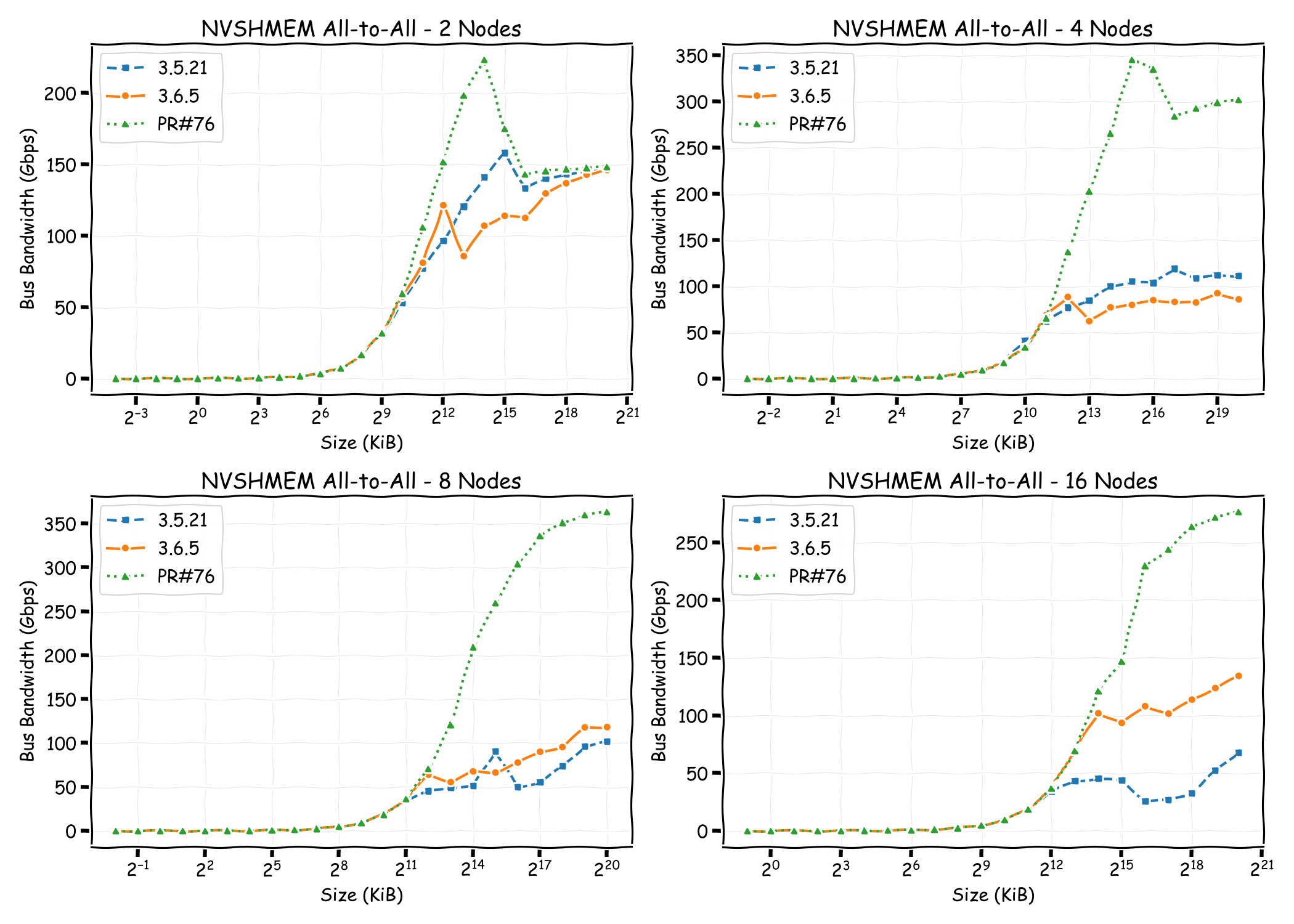
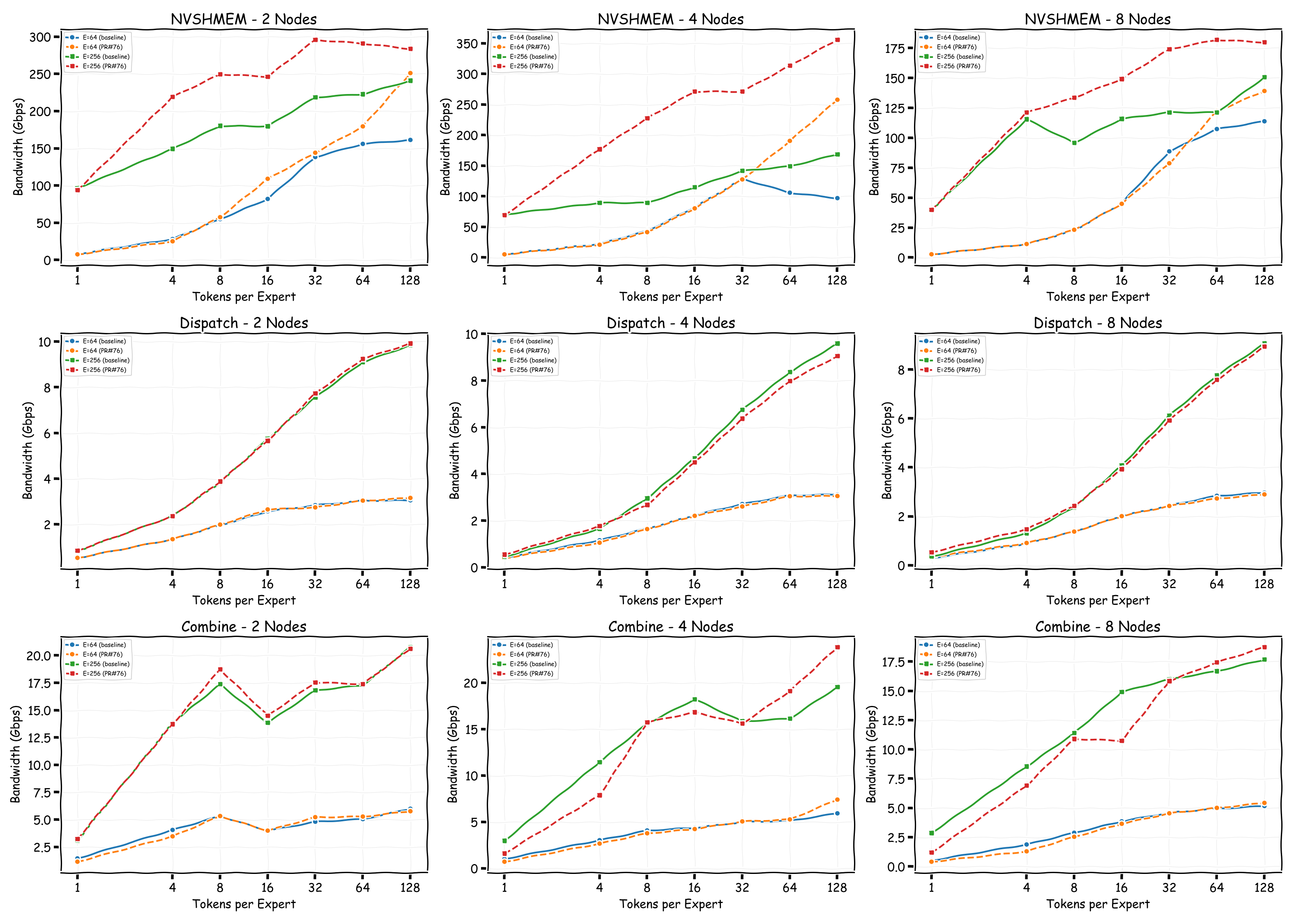
We also compare the all-to-all bandwidth across different node counts for NVSHMEM 3.5.21, NVSHMEM 3.6.5, and NVSHMEM 3.6.5 with the Rx imbalance fix. With the fix applied, throughput is significantly higher than both other configurations. Notably, without the fix, even though NVSHMEM 3.6.5 utilizes multiple NICs for Tx, the Rx imbalance becomes a bottleneck—resulting in throughput that can be lower than single-NIC mode, as observed in the 2-node and 4-node cases.
pplx-kernels All-to-All#
With NVSHMEM 3.6.5 (without the Rx imbalance fix), all Tx and Rx NICs are active. Although Rx traffic is slightly imbalanced, the MoE dispatch kernel itself may distribute tokens unevenly across experts, contributing to the imbalance.
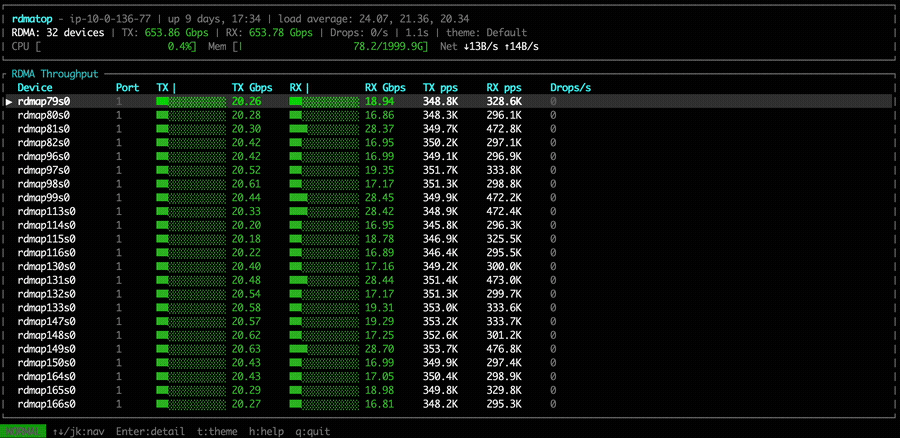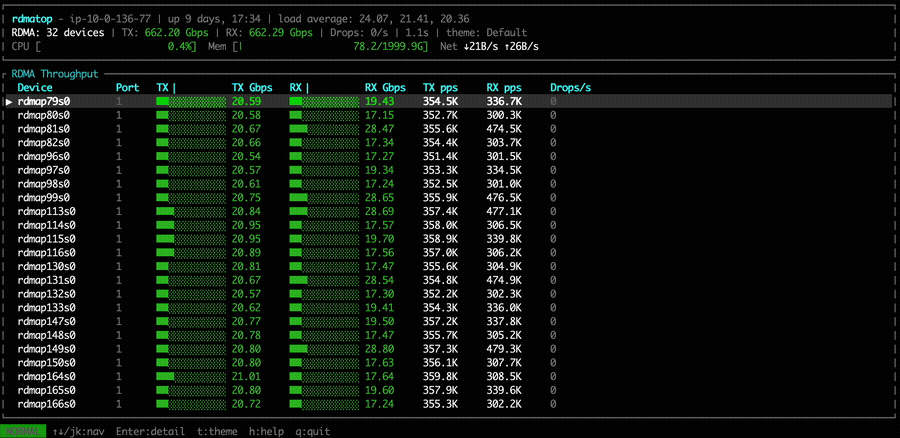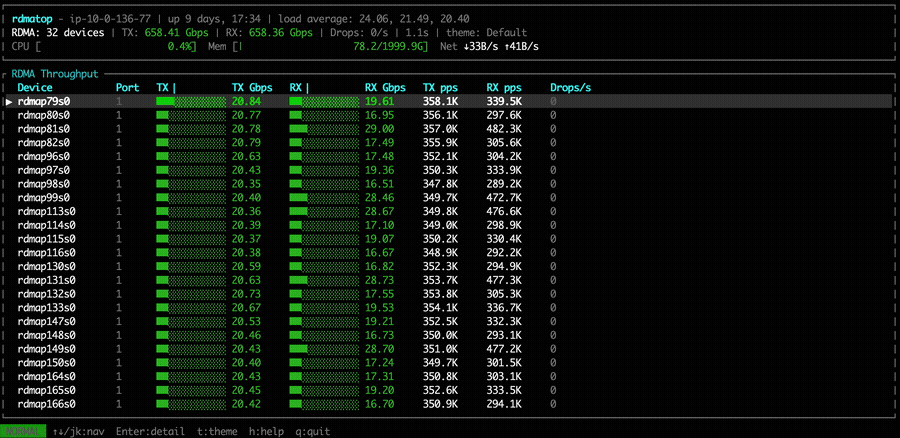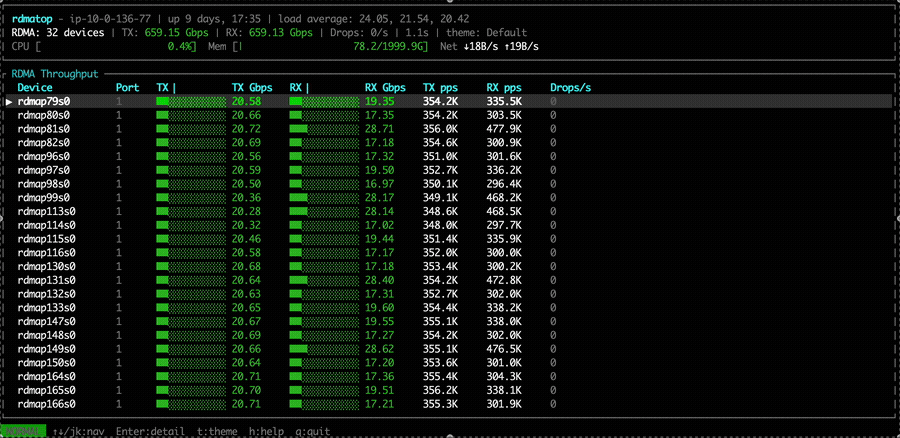
With NVSHMEM 3.6.5 and the Rx imbalance fix applied, all Tx and Rx NICs remain active, and Rx traffic appears relatively more balanced. However, the MoE dispatch and combine bandwidth shows no significant difference compared to the unfixed version.
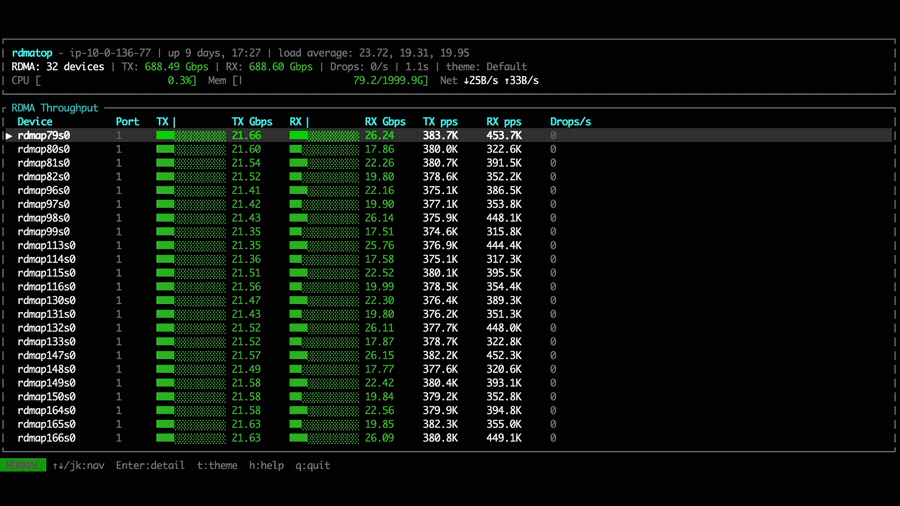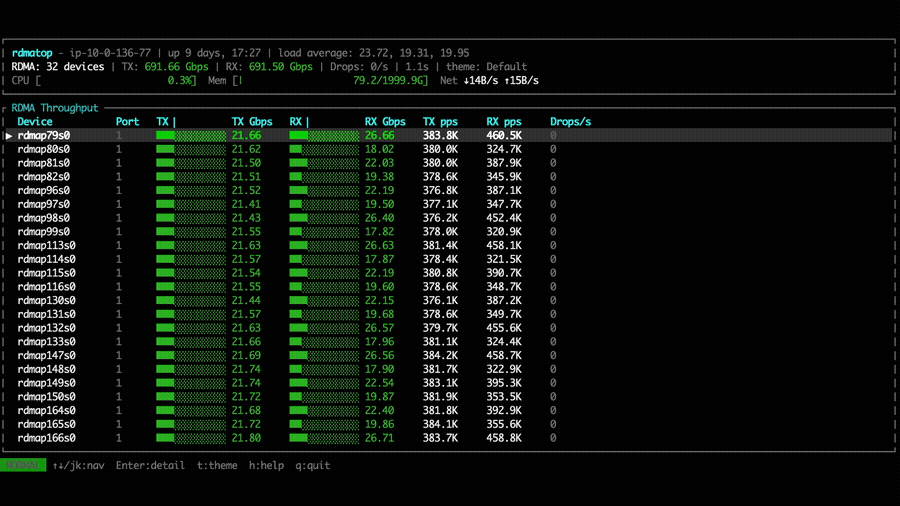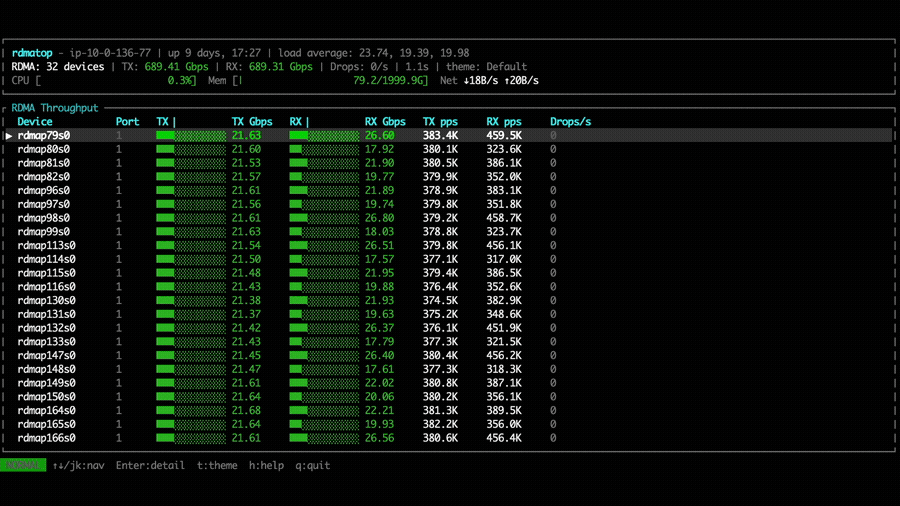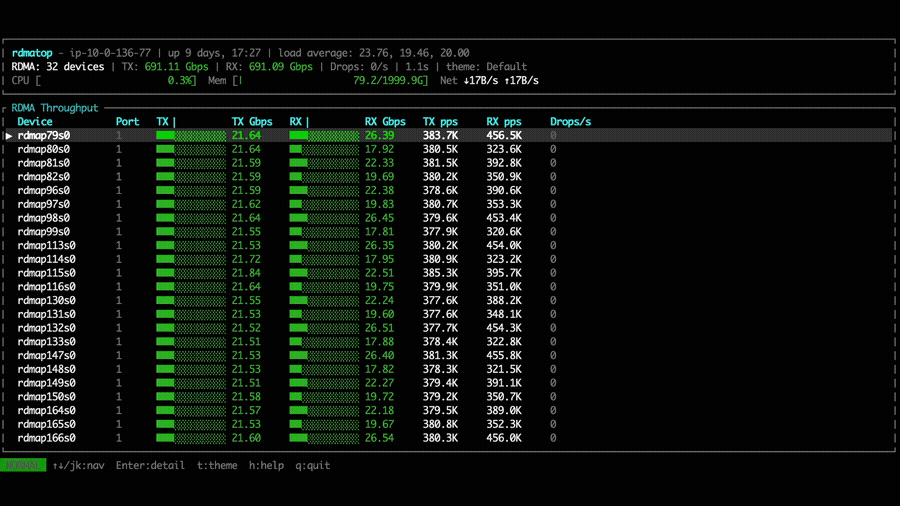
Comparing the two configurations, NVSHMEM bandwidth is relatively higher with the Rx imbalance fix applied. However, other factors such as kernel computation may dominate the overall MoE kernel performance, resulting in similar dispatch and combine throughput between the two versions.
Conclusion#
NVSHMEM 3.6.5 introduces multi-NIC support for the libfabric transport, enabling round-robin NIC selection on AWS instances equipped with multiple EFA NICs. Our experiments confirm that this feature allows both point-to-point and all-to-all NVSHMEM operations to distribute traffic across all available NICs, significantly increasing aggregate bandwidth compared to older NVSHMEM versions.
However, we identified an Rx imbalance issue in the initial 3.6.5 release, where all PEs select the same round-robin target NIC simultaneously, causing Rx traffic to converge on a single NIC. This imbalance can degrade all-to-all throughput to levels below single-NIC mode in certain configurations. A proposed fix addresses this by offsetting the round-robin selection per PE, resulting in balanced Rx traffic and substantially improved all-to-all bandwidth.
For pplx-kernels, multi-NIC support successfully distributes traffic across all EFA NICs. While NVSHMEM-level bandwidth improves with the Rx fix, the end-to-end MoE dispatch and combine throughput shows minimal difference, suggesting that kernel computation rather than network bandwidth is the dominant factor in these workloads.
Overall, multi-NIC support in NVSHMEM 3.6.5 is an important step toward enabling NVSHMEM-based MoE kernels to fully utilize the network capacity of AWS GPU instances, and can potentially improve MoE kernel throughput for large-scale LLM training and serving workloads.